Camera Resolution for Machine Learning
15th October 2020
Editor’s Note: article updated in October 2024 for comprehensiveness.

Computer Vision is all about objects and in an ideal world this would mean seeing a complete outline, and content of a single object to be identified, against a contrasting plain, background.
But, we’re in the real world. We need to achieve a high level of confidence where an object is partially obscured, at an angle, badly lit, among other similar objects, at a distance, etc. – this is the magic provided by inference based on good models that are, in turn, based on lots of sample images of the desired object.
Video camera technology constraints
When it comes to capturing video images for computer vision, affordable video camera technology has known constraints and understanding both its capabilities and limitations is key.
Let me explain, the human eye usually works in pairs (not mine, but that’s not the focus of this blog…) and your brain works with your eyes to rapidly scan the field of view and direct the view to concentrate on specific objects.
The stereo view also gives a distance cue that is improved by movement of the head. This is really useful when distinguishing between small objects close to and similar, larger objects that are further away.
By contrast, video cameras provide a fixed view of objects as they pass through the field of view. You could have stereo cameras with variable zoom that pan and tilt to simulate a human head with eyes and neck muscles, but that is expensive.
So, let’s think about pixels. There is a trade-off between resolution and performance with machine learning hardware. A higher resolution means more objects can be resolved, but there is more visual information to process. Camera resolution is in pixels and modern vision sensors can deliver a lot of them. It is easy find 5 Megapixel cameras – meaning they can deliver a native resolution of 2560*1920.
However, there is a trade-off between resolution and performance with machine learning hardware.
A higher resolution means more objects can be resolved, but there is more visual information to process. This is a problem – to handle this many pixels in an image requires a lot of computation and with typical edge computing hardware will limit the frames per second (fps) that can be handled, typically to low single figures. You will also find that low-cost 5 Megapixel cameras often cannot deliver the maximum resolution at a reasonable frame rate – expect 5fps, not 30.
Two additional factors that need to be understood are reduction of blurring of the image due to movement and reduction of graininess of the image due to low light. For those of you who had a 35mm film camera, do you remember selecting ISO and shutter speed? For smartphone users, you may have noticed that you only see blur and graininess on subjects moving at speed in dimly lit scenes.
CCTV cameras (and smartphones) can produce sharp, well-defined images in good light. For best results, please set your camera to the equivalent of 1/250 second shutter speed and check the images for graininess and if necessary, either improve the lighting or spend extra for a camera with a more sensitive image sensor.
With all this in mind, choose your resolution carefully. If the objects to be detected are stationary, then the framerate can be very low; alternatively, if the intent is to recognize a moving object – for example, a face in a crowd or a vehicle on a motorway, then resolution should be lower to allow a higher frame rate.
How many pixels define an object?
This brings us to the question of resolution. One way of looking at this is to specify a camera that will fit the ML requirements for your computer vision application – this comes down to:
- The width of the scene – for the object to be detected with a high degree of certainty it’s recommended that it should occupy 10% of the field of view
- The distance between camera and object
- Size of the object: a human head, say 50 pixels; a vehicle registration plate, 75 pixels across the plate
- The focal length of the camera lens – effectively the magnification of the image
- The horizontal resolution of the camera.
For example, most cameras – even relatively cheap ones, can manage 25fps at 1280*720 and this will give good results in most cases.
Example of a computer vision ML requirement with a ‘standard’ modern CCTV camera
So, let’s say we want to count the number of individuals wearing the correct Personal Protection Equipment (PPE) – this used to mean hard hat and high vis jacket – now it’s facemasks. The process of PPE recognition depends first on discriminating people, then individual heads, then checking with a second model the wearing of PPE. So, we need to begin by detecting human heads – please note at SeeChange we do not actually identify people!
Assuming object is a human head 150mm wide at 50 pixels per head gives a desired resolution of 350 pixels per meter.
The numbers below are entered into an online field-of-view (FOV) calculator – try out the one below. It allows the calculation of the size of the image area at a distance given sensor size and lens focal length. Note that you can define a required area and distance to target to determine the lens focal length. There are many more FOV calculators online, for example https://www.jvsg.com/calculators/cctv-lens-calculator/
Using the calculator linked above, let’s see what works in terms of camera model, lens focal length and distance to the target:
- Sensor size = ¼” (check the camera datasheet for this)
- Focal length of the camera lens = 2.8mm
- Width of scene = 3.8m
- Distance between camera and object = 3m
- Height of camera = 3m
- Horizontal resolution of the camera = 1920
This would be a good start, giving a pixel density of 354 pixels per metre, and if the camera needs to be located further away, we could select a different focal length lens.
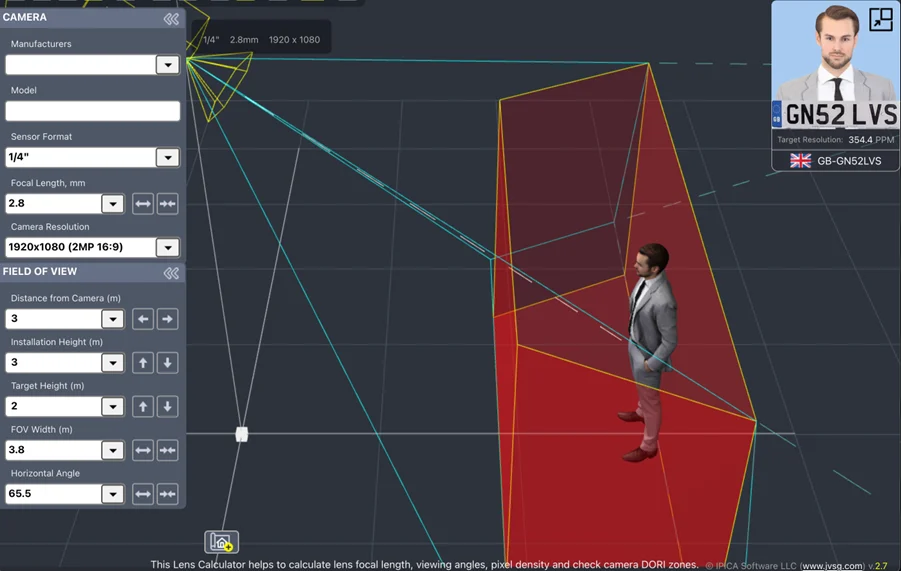
Note how this calculator takes the numbers you entered to illustrate a 3D-model of the field of view
The image top-right shows an expected detail view, together with a calculated pixel density.
What’s next?
It should be noted that there are other ways of improving the confidence of an object, in certain special cases.
For example, it is possible to stack successive images to improve identification of simple objects, such as a rectangular vehicle registration plate. The plate can be identified and transformed from multiple images (think moving vehicle) showing the plate at various angles and different sizes, to a regular rectangle of fixed size; this can lead to improvement of recognition of the characters on the plate. Identification is helped because we know we are looking for specific character combinations.
A final thought – color correction
This is usually not a problem for object detection where objects are recognized by similar shapes, curves, surface texture, etc.; one area where it does matter is in in the identification of fruit and vegetables.
A colour cast to lighting or reflection of a strong colour from signage, etc. can be a problem. Consider that all machine learning models are trained using datasets of typically thousands of images of fruit where those images were collected under typical store lighting. It is easy to see the colour difference between a lime and a lemon, for example.
Now illuminate your subject with red or blue light and note the difficulty to distinguish lemons and limes by their colour. A colour cast can lead to mis-judgements about the ripeness of fruits and vegetables. For instance, a blue-tinted light might make a green vegetable appear more yellow, suggesting it is riper than it actually is. Different varieties of fruits and vegetables often have subtle colour differences. A colour cast can obscure these distinctions, making it harder to accurately identify specific types.



